Paul
Oct 28, 2024
Tables of Content |
|
A Text-to-Speech (TTS) API is a powerful tool that converts written text into spoken words, enabling businesses and developers to integrate voice technology into applications, websites, and services. TTS APIs are especially useful for enhancing accessibility, improving user experience, and automating tasks that require voice interactions, such as virtual assistants, customer service chatbots, and more.
In this blog, we’ll break down exactly what a TTS API is, how it works, and why it’s important for modern businesses looking to innovate through voice technology. You’ll learn the key components, benefits, and use cases, as well as how to choose the best TTS solution for your specific needs. We will also explore the various speech API features that make these tools indispensable for modern applications.
Key Takeaways
- A Text to Speech API converts written text into spoken words using advanced technology, enhancing user interaction with content.
- Different types of TTS APIs, such as cloud-based, on-premise, and neural TTS, cater to various needs, offering flexibility in deployment and speech quality.
- Key benefits include improved accessibility for visually impaired users, enhanced productivity in professional settings, and applications across e-learning, media production, and customer service.
Introduction to Text to Speech
Text-to-speech (TTS) technology is a form of speech synthesis that converts written text into spoken words. This technology has been around for several decades, with its roots tracing back to the 1960s. Early TTS systems were rudimentary, producing robotic and unnatural-sounding speech. However, with advancements in artificial intelligence, machine learning, and natural language processing, TTS has evolved significantly. Modern TTS systems can generate speech that is almost indistinguishable from human speech, offering a more natural and engaging user experience.
Importance of Text to Speech in Modern Applications
In today’s digital age, TTS technology plays a crucial role across various applications. One of its most significant contributions is in the realm of accessibility. For individuals with visual impairments or reading disabilities, TTS provides a way to access written content that would otherwise be inaccessible. This technology is also invaluable in educational settings, where it can aid in learning and comprehension by providing auditory support. In the entertainment industry, TTS is used to create engaging audio content, such as audiobooks and podcasts. Additionally, in customer service, TTS enables automated systems to interact with customers in a more natural and efficient manner, enhancing the overall user experience.
What is a Text to Speech API?

A Text to Speech API is a powerful tool that technology converts written text into spoken words, enabling dynamic interactions with content. This technology is achieved through sophisticated software, linguistics, and artificial intelligence, ensuring that the spoken output is as natural as possible. The API allows users to send text data and receive high-quality, human-like audio outputs in response.
APIs, or Application Programming Interfaces, act as bridges between different software systems, allowing them to communicate and exchange data seamlessly. For instance, when you use a speech API, you are essentially leveraging a set of predefined functions that convert text into speech without having to write the code from scratch. This not only simplifies integration but also enhances the functionality of your application by incorporating advanced features. For instance, managing your TTS API can be easily done through the Google Cloud Platform dashboard, where you can enable or disable the API and monitor its usage.
The use of machine learning and deep learning models further improves the quality and naturalness of the synthesized speech. These models continuously learn from real human speech, improving the expressiveness and accuracy of the generated audio, making it nearly indistinguishable from a real human voice.
How Does a Text to Speech API Work?
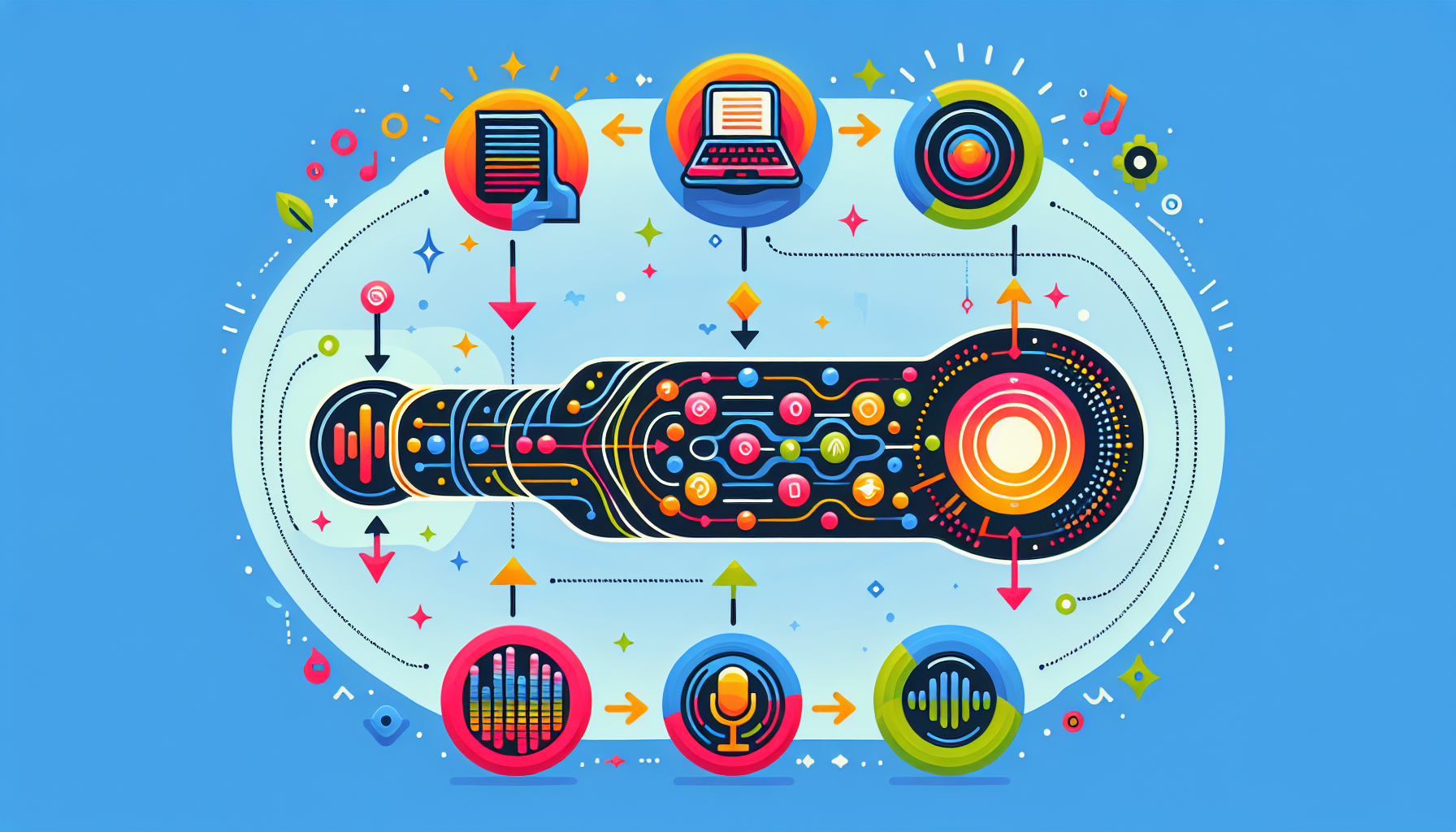
Step by Step Process |
|---|
📝 Step 1: Input Text Think of this as feeding the API a message to “read aloud.” You give it the text, like handing a script to an actor.
🔄 Step 2: Text Analysis Now the API acts like a language expert. It breaks down the text into smaller parts (words, sentences), understanding how each word should be pronounced. It’s like the actor studying the script and figuring out how to say each line clearly.
🧠 Step 3: Language Processing Next, the API becomes a voice coach, analyzing things like intonation, pitch, and emphasis. It’s as if the actor is learning where to stress certain words to give the best performance!
🎤 Step 4: Speech Synthesis This is the magic moment! The API transforms the text into sound, like turning words into music. The actor finally speaks, and you hear the voice come to life in real-time.
📤 Step 5: Audio Output The API delivers the speech in your chosen format (like MP3 or WAV), ready for use in your apps or devices. It’s like getting the recorded performance, ready to share with your audience.
Each step happens in the blink of an eye, allowing you to integrate realistic, high-quality voice interactions into your project with ease! 🎧 |
A Text to Speech API starts with an API call where you send the input text data you wish to convert. This text can be in plain format or enhanced using Speech Synthesis Markup Language (SSML), which allows for more precise control over the speech output. These speech API features include advanced text analysis, natural language processing, and high-quality speech synthesis, which together ensure a seamless and natural user experience. After receiving the text, the API performs text analysis to interpret the input, considering punctuation, abbreviations, and context for accurate pronunciation.
The speech synthesis process follows, converting the analyzed text into audio data. Natural Language Processing (NLP) boosts the quality of the generated speech by improving its accuracy, naturalness, and expressiveness. Advanced models, such as WaveNet, are used to produce voices that sound incredibly natural and lifelike.
The synthesized speech is then returned as an audio file in various formats like MP3 or LINEAR16. This audio data is often base64-encoded and must be decoded to produce the final audio output. And just like that, your text has been transformed into spoken words.
Key Components of Text to Speech APIs
Several key components make Text to Speech APIs effective. The Google Text to Speech API, for example, can convert text into audio recordings such as MP3, Linear16, and OGG Opus. This API supports a maximum audio length of 1 million bytes in a single session, ensuring that even lengthy texts can be converted seamlessly.
- Speech synthesis is at the heart of these APIs, converting text input into spoken audio using advanced algorithms to generate human-like speech. Voice customization options allow users to personalize the output by choosing from various voice options (gender, accents, tones) and adjusting pitch, speed, and volume. This customization ensures that the synthesized voice aligns perfectly with the desired application.
- Language support is another critical feature, with many APIs offering multilingual capabilities. This is particularly useful for applications targeting a global audience.
- Additionally, Speech Synthesis Markup Language (SSML) provides developers with control over speech output using tags for pronunciation, pauses, emphasis, and tone adjustments.
- Real-time streaming capabilities enable immediate voice responses, making these APIs ideal for interactive applications. The synthesized speech can be exported in various formats, such as MP3 or WAV, offering flexibility for use across different platforms and applications.
- Secure access is maintained through API keys and authentication, ensuring data privacy and integrity. Additionally,
Creating Custom Voices
Creating custom voices is a key aspect of TTS technology, allowing users to personalize their experience and create unique voices that align with their brand identity or target audience preferences. Custom voices can be created using various techniques, including voice cloning, voice morphing, and voice synthesis. Voice cloning involves recording a person’s voice and using machine learning algorithms to create a digital replica that can speak any text input. Voice morphing allows users to modify existing voices by changing parameters such as pitch, tone, and speed. Voice synthesis, on the other hand, involves generating entirely new voices using advanced algorithms. These techniques enable businesses to create distinctive voices that enhance their brand and provide a more personalized user experience.
Types of Text to Speech APIs

Text to Speech APIs come in various forms, each suited for different needs and environments.
- Cloud-based APIs, such as Google Cloud TTS and Amazon Polly, are hosted on external servers. They allow developers to access cloud text to speech services via an internet connection without managing the underlying infrastructure. For instance, Google Cloud TTS can be managed through the Google Cloud Platform dashboard, providing an easy way to configure and monitor the API.
- On-premise APIs, on the other hand, are installed and run locally on an organization’s servers, offering more control over data security and privacy. This is particularly beneficial for sensitive environments where data protection is paramount.
- Neural TTS APIs use advanced neural networks to produce highly realistic and natural-sounding speech, as exemplified by services like Microsoft Azure Neural TTS.
- Embedded TTS APIs are designed to work within specific devices or systems, such as mobile applications or IoT devices, without needing internet access for real-time voice generation.
- Multilingual TTS APIs support speech synthesis in multiple languages and dialects, catering to a global audience. Real-time TTS APIs generate and stream speech as text is input, making them ideal for live interactions.
- Customizable Voice APIs enable developers to create unique voices or adjust parameters like pitch, tone, and speed for personalized outputs.
- Lastly, interactive TTS APIs are used in conversational AI platforms like chatbots and virtual assistants, facilitating ongoing dialogues.
Benefits of Using Text to Speech APIs

The benefits of using Text to Speech APIs are vast and varied. A significant advantage is the enhancement of accessibility, particularly for visually impaired users. By converting written content into spoken language, TTS technology makes information accessible to a broader audience. This is vital in educational settings and everyday interactions.
In professional settings, TTS improves productivity by assisting with tasks such as proofreading and editing through auditory feedback. Additionally, it helps reduce reading fatigue by allowing users to listen to text rather than reading it visually. This is particularly beneficial during long reading sessions or when multitasking.
Customer service is another area where TTS APIs shine. Automated voice agents can handle inquiries efficiently, enhancing operational efficiency and providing a better user experience. Overall, the accessibility features and usability improvements offered by TTS technology enhance user experience across various applications.
Common Applications of Text to Speech APIs
Text to Speech technology finds its place in numerous applications. In e-learning environments, TTS provides audio support for better comprehension and engagement for learners. Media production extensively uses TTS for generating voiceovers in videos, podcasts, and advertisements, increasing user engagement.
Interactive Voice Response (IVR) systems utilize TTS to manage calls effectively, providing information and routing calls to appropriate departments. Language learning applications benefit from TTS by offering users auditory exposure to correct pronunciation and comprehension. Moreover, TTS allows users to multitask efficiently by enabling them to consume information during activities like commuting or exercising.
In smart home devices and IoT applications, TTS provides voice feedback for better user interaction with technology. Virtual assistants and multimedia projects frequently integrate TTS to deliver a seamless user experience. In healthcare, TTS APIs streamline communication between patients and healthcare providers, improving the overall delivery of care. Some TTS APIs are specialized for certain languages or dialects, providing optimized output for specific regional accents.
Setting Up a Text to Speech API Project
Setting up a Text to Speech API project requires several steps:
- First, enable the API in your cloud platform project. For example, using the Google Text-to-Speech API requires enabling it in the Google Cloud Platform dashboard and setting up billing for the associated project.
- After enabling the API and setting up billing, follow the specific instructions provided in the cloud documentation for authentication setup. This usually involves creating a Google Cloud project and linking it to a billing account to generate an API key.
- You can test the Text-to-Speech API through a ‘TRY THIS API’ option without linking it to your project, making it easier to experiment with the API.
Important Features to Look for in a Text to Speech API: Natural Sounding Speech
Several features are crucial when selecting a Text to Speech API. High-quality voices are a key factor for great user experience and brand perception, with studio voices providing professional-sounding output. Lalals.com text to speech voices are known for their human-like quality and natural intonation. Customization options allow users to tailor the audio output by adjusting speech rate, pitch, and volume.
Support for multiple languages broadens the API’s usability for diverse audiences, making it ideal for global applications. Robust customization options and the ability to use SSML enhance the speech output by enabling features like pauses and proper pronunciation of acronyms. Certain APIs, like IBM Watson, offer features for creating unique branded voices to boost customer engagement.
Troubleshooting Common Issues with Text to Speech APIs
Troubleshooting common issues with Text to Speech APIs often involves addressing authentication errors and audio quality problems. Common authentication issues include incorrect API keys or tokens, leading to failure in making API requests. To resolve these errors, verify that you are using the correct API keys and review your application’s access permissions.
Audio quality issues might arise from insufficient parameters, improper voice selection, or low bitrate settings. To improve audio quality, select appropriate voice settings and adjust the bitrate according to the desired output standards.
Summary
Text to Speech APIs represent a remarkable advancement in how we interact with digital content. They offer a seamless way to convert written text into spoken words, changing accessibility and user experience. The technology leverages machine learning and AI to produce high-quality, natural-sounding speech, making it indispensable in various applications, from e-learning to customer service.
Understanding the different types of TTS APIs and their key components helps in selecting the right API for your needs. Setting up a TTS project involves enabling the API, setting up billing, and following authentication procedures, all of which are straightforward with the right guidance.
In conclusion, the future of Text to Speech technology looks bright, with continuous improvements in naturalness and expressiveness. As we embrace this technology, we can expect even more innovative applications that will transform our interaction with digital content. The spoken word, powered by artificial intelligence, is here to stay.
Frequently Asked Questions
What is a Text to Speech API?A Text to Speech API takes your written words and turns them into spoken audio using advanced technology and AI. It's a great way to make content accessible or create engaging audio experiences! |
How does a Text to Speech API work?A Text to Speech API works by sending your text to the service, which analyzes it and converts it into audio, then sends back the spoken version in different audio formats. It’s a neat way to turn written words into voices! |
What are the types of Text to Speech APIs?There are several types of Text to Speech APIs, including cloud-based, on-premise, neural TTS, and multilingual options. Choosing the right one depends on your specific needs for customization and interactivity. |
What are the benefits of using Text to Speech APIs?Using Text to Speech APIs boosts accessibility for visually impaired users and enhances productivity by reducing reading fatigue. They also improve customer service, making information more easily accessible for everyone. |
How do I set up a Text to Speech API project?To set up a Text to Speech API project, you'll need to enable the API in your cloud platform, configure billing, and complete the authentication process. Once you've done that, go ahead and test the API to ensure everything works smoothly. |
Convert Your Voice with AI
Make your voice sound like those of famous arists.
Join Lalals and use our hyper-realistic voice converter now.